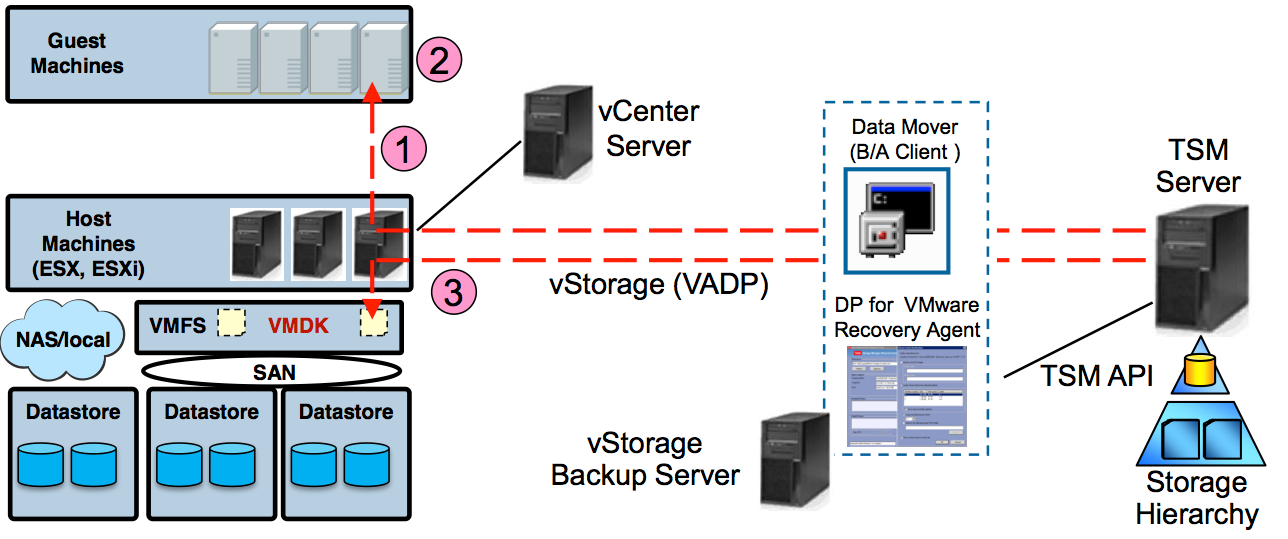
Dans le cadre d'un PRA et afin de respecter les contraintes de RTO (Recovery Time Objective) et RPO (Recovery Point Objective) imposées il peut être très judicieux de faire appel à la fonction de réplication des postes disponible depuis TSM 6.3.
La réplication : qu'est ce que c'est ?
Pour rappel, la réplication consiste à copier de manière incrémentale les données appartenant à un ou plusieurs clients de sauvegarde/archivage depuis une serveur TSM source vers un serveur TSM cible en utilisant les liaisons réseaux disponibles.
On parle alors d'externalisation électronique puisqu'il n'est plus nécessaire de faire appel à des médias physiques (bandes LTO par exemple) afin de disposer d'une copie des données sur un site de secours.
La réplication peut être utilisée pour les différents types de données suivants :
- données de sauvegarde actives & inactives ou uniquement actives
- données d'archivage
Pré-requis techniques
Il est impératif d'utiliser une version TSM6.3.0 minimum sur les deux serveurs afin de pouvoir utiliser la réplication.
- TSM 6.3.0
- Liste des OS supportés
- Administration Center v 6.3 (pour gérer la réplication en mode graphique)
- 32GB de mémoire minimum, 64GB recommandé
- Bande passante suffisante afin d'effectuer les réplications planifiées
Mise en place
Définition des serveurs
La première étape consiste tout d'abord à définir sur chacun des deux serveurs les paramètres qui leur permettront d'accéder l'un à l'autre.
Depuis le serveur cible :
Si ce n'est pas déjà le cas, il faut définir le mot de passe serveur. Ce mot de passe sera utilisé par la réplication lors des connexions server-to-server.
Il faut ensuite créer la définition du serveur source en précisant en autre son adresse IP (hla) ainsi que le port TCP qu'il utilise (lla)
Pour vérifier si cette dernière fonctionne correctement vous pouvez utiliser la commande "ping" depuis une invite de commande TSM.
Depuis le serveur source :
Il faut créer une nouvelle définition qui fera référence au serveur cible puis activer la réplication.
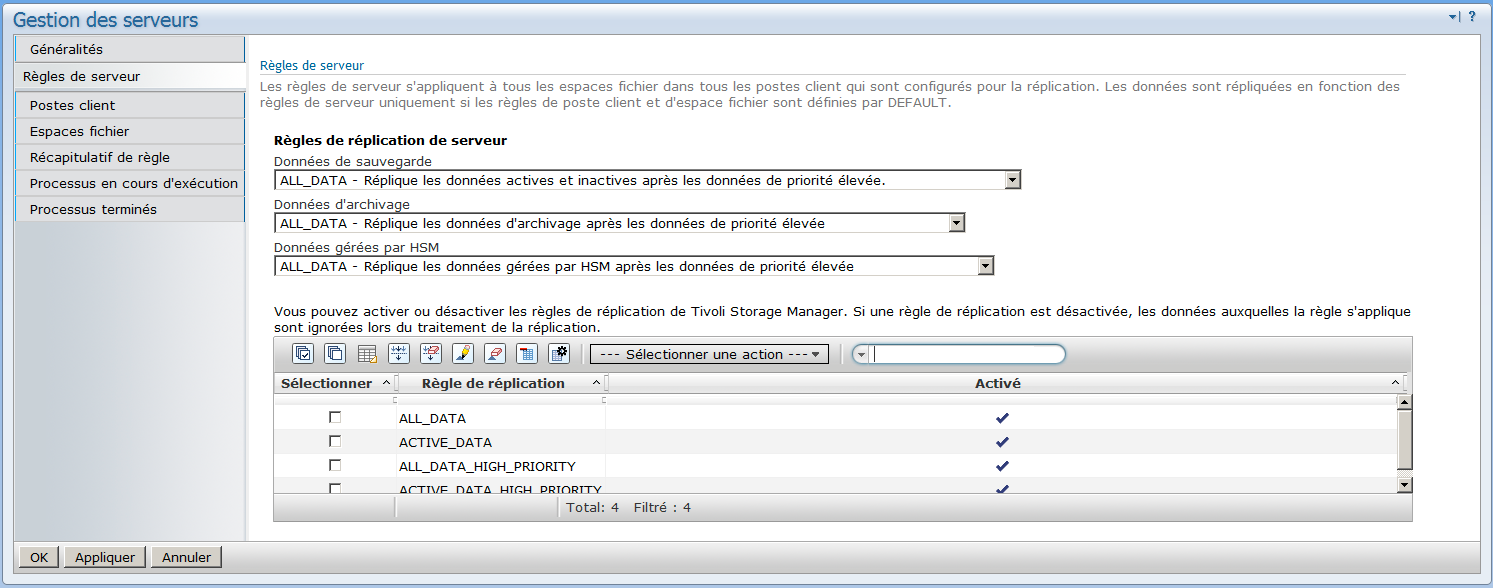
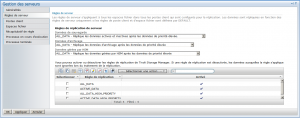
Règles de réplication par défaut
Lors de la réplication des données il est possible de spécifier le type de données que vous souhaitez répliquer (sauvegarde, archive, données actives uniquement, ...)
Si, pas exemple, vous souhaitez répliquer l'intégralité des données il suffit d'utiliser la commande TSM suivante :
set bkreplruledefault ALL_DATA
Vous pouvez par exemple choisir de ne répliquer que les données de sauvegarde actives via l'option ACTIVE_DATA.
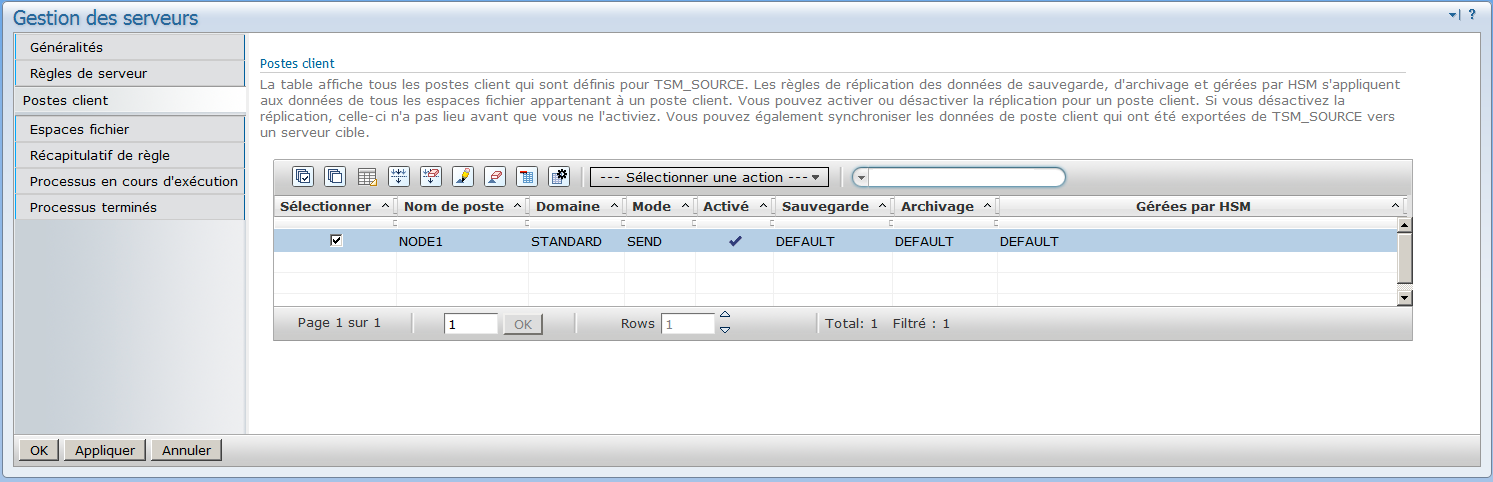
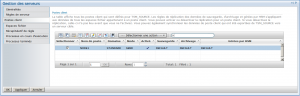
Configuration des postes clients pour la réplication
Nous partons du principe que les postes clients n'existent pas sur le serveur cible et que leur première réplication sera effectuée à travers le réseau.
Pour chaque node que vous souhaitez répliquer il faut activer la réplication (option replstate)
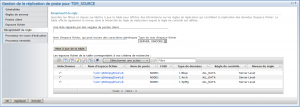
Réplication de plusieurs postes clients. Comment gagner du temps ?
Si vous souhaitez répliquer plusieurs postes clients à la fois, voir même l'intégralité des postes présents sur votre serveur TSM source, il est conseillé d'utiliser des groupes de nodes.
Pour pourrez par ailleurs hiérarchiser vos réplications en mettant en place différentes règles de priorités.
Test : réplication manuelle
Pour tester le bon fonctionnement de la réplication, il suffit d'utiliser la commande TSM replicate node
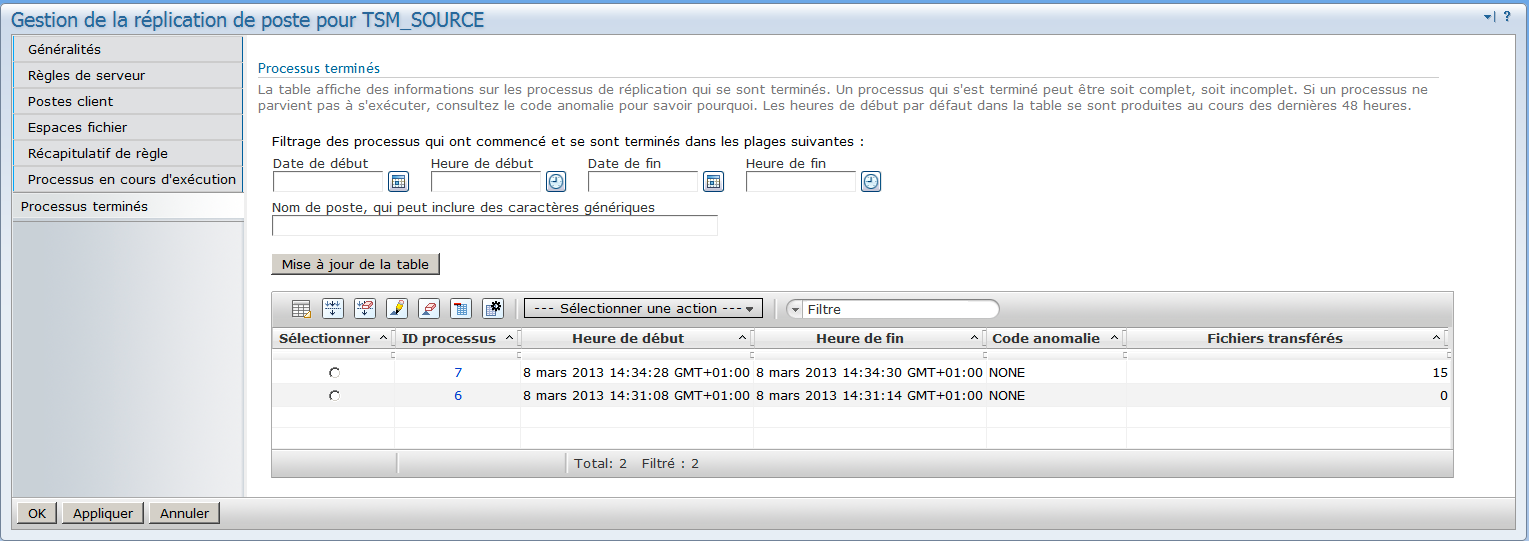
Pour contrôler l'état de la réplication vous pouvez alors utiliser les commandes "q pr" et "q actlog" puis vous assurez que le node a été créé sur le serveur cible et qu'il contient bien des données.
ANR0327I Replication of node NODE1 completed.
Filesccurrent: 0. Files replicated: 15 of 15. Files updated: 0 of 0.
Files deleted: 0 of 0. Amount replicated: 15 KB of 15 KB.
Amount transferred: 15 KB.
Elapsed time: 0 Day(s), 0 Hour(s), 1 Minute(s). (SESSION: 3, PROCESS: 7)
ANR0986I Process 7 for Replicate Node running in the
BACKGROUND processed 15 items for a total of 15,360 bytes
with a completion state of SUCCESS at 14:34:30.
(SESSION: 3, PROCESS: 7)
Réplication initiale
Il existe plusieurs méthode qui dépendront principalement de vos besoins de réplication ainsi que de la bande passante disponible entre les deux serveurs TSM.
- Réplication via le réseau : si vous disposez d'une bande passante suffisante que vous n'être pas pressés par le temps cette méthode reste la plus simple. Il suffit de lancer les réplications qui s’effectueront intégralement à travers le réseau. Vous pouvez effectuer les choses de manière progressive en sélectionnant les nodes ou les groupes de nodes les plus prioritaires.
- Réplication des données actives uniquement : dans un premier temps vous pouvez choisir de ne répliquer que les données actives de vous comptes, ces dernières étant généralement les plus stratégiques. Une fois cette première réplication terminée, vous pourrez alors modifier les règles en activant la réplication des versions actives et inactives.
- Export/Importe via médias physiques : si vous devez répliquer une grosse quantité de données et que vous ne pouvez pas vous permettre d'effectuer rapidement cette opération à travers le réseau, vous avez la possibilité d'effectuer des exports / imports entre votre serveur source et votre serveur cible en utilisant par exemple des cartouches LTO. Il faut cependant être rigoureux au moment de l'activation de la réplication afin que les données soient dans un premier temps synchronisées (options syncsend et syncreceive) Une fois la synchronisation terminée les comptes seront automatiquement mis à jour par TSM pour se répliquer.
Automatisation de la réplication
Il suffit de créer un schedule de type commande.
define schedule REPLICATION_NODE1 type=admin cmd="replicate node NODE1 wait=yes" desc="Replication quotidienne du poste NODE1" dayofweek=any period=1 perunits=days active=yes starttime=00:00
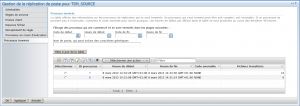
Gestion de la réplication via l'Administration Center (AC)
Il est possible de gérer la réplication de manière graphique à travers l'AC en version 6.3 minimum.
Règles de serveur :
Sélection des postes clients à répliquer :
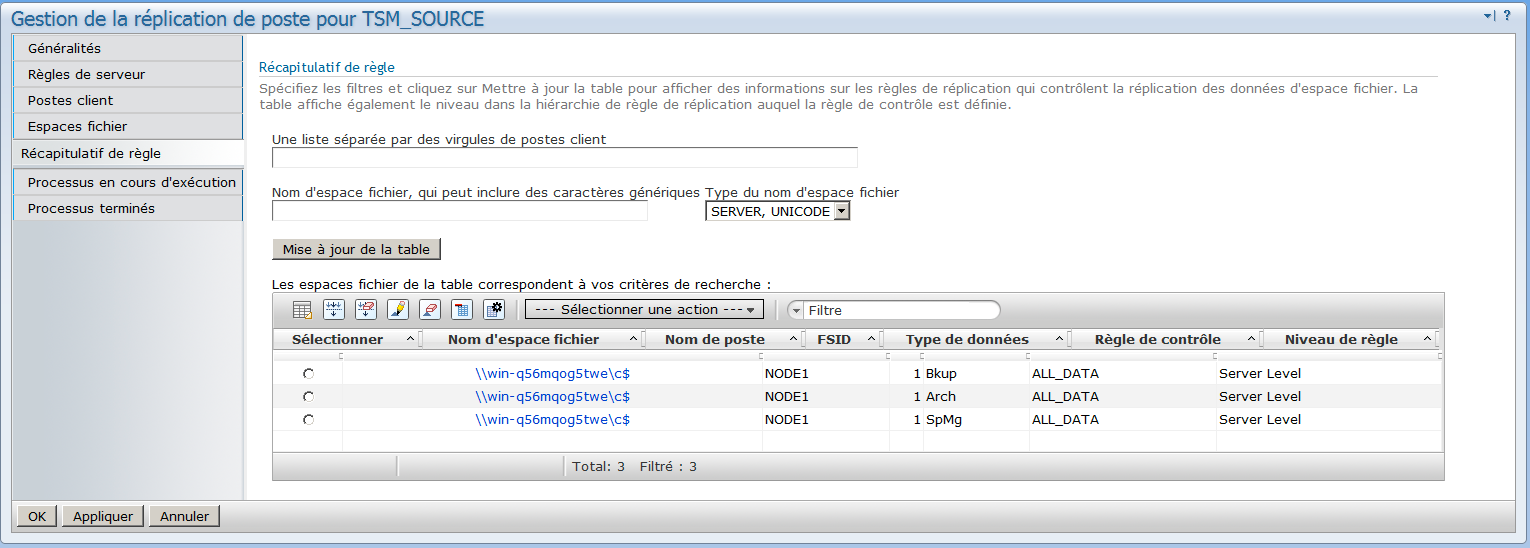
Récapitulatif des règles :
Historique des réplications :
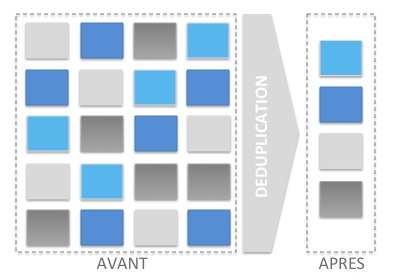
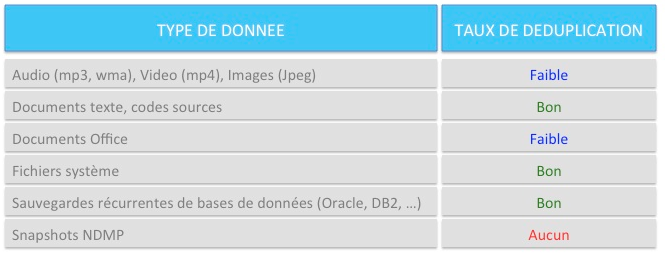
Optimisation : réplication & déduplication
Mettre en place la déduplication peut vous permettre d'améliorer les temps de réplication car les blocs de donnés (les chunks) déjà existants sur le serveur cible ne seront pas à nouveau transférés.
Cela implique cependant de revoir les pré-requis en terme de RAM, ce process était relativement gourmand. Tout dépend bien évidemment de la taille de votre architecture, mais il est cependant recommandé par IBM d'avoir un minimum de 64GB de mémoire pour utiliser la déduplication en combinaison de la réplication. Ne pas respecter ce minimum peut entrainer des baisses de performances globales de votre architecture TSM en pénalisant les autres opérations.
DRP TSM : 100% electronic vaulting
En associant la réplication des comptes TSM à la synchronisation de vos bases TSM via HADR il est alors possible de mettre en place un DRP 100% électronique (eletronic vaulting)
Pour plus d'infos sur DB2 HADR consultez notre article sur le sujet : Optimisation du DRP TSM avec DB2 HADR
Des questions ?
Vous avez des questions concernant cet article ? Laissez-nous un commentaire ou contactez-nous directement via notre formulaire de contact.
Nous vous répondrons dans les plus brefs délais.